오픈소스 프로젝트에 소스코드 기여해보기 - GNOME문자표에 한글표기와 베트남어발음추가(add Korean Hangul and Vietnamese pronunciation on GNOME gucharmap)
(English follow Korean. 영어는 한국어 뒤에 나옵니다.)
GNOME - GNU Network Object Model Environment
한국어 소개: 그놈(GNOME) 프로젝트는 사용자를 위한 완전히 자유롭고 사용하기 쉬운 데스크탑 환경과 동시에 소프트웨어 개발자를 위한 강력한 어플리케이션 프레임워크를 만들고 있습니다.그놈은 GNU 프로젝트의 일부이며, 자유 소프트웨어입니다(흔히, 오픈 소스 소프트웨어라고 불립니다). 그놈은 많은 BSD와 GNU/리눅스에 포함되어 배포되고 있으며, 다른 여러 UNIX 시스템에서도 작동합니다.
GNOME Homepage - https://www.gnome.org/
GNOME Korea Homepage - http://www.gnome.or.kr/
GNOME Korea Blog - http://gnome-kr.blogspot.kr/
gucharmap - the GNOME Character Map, based on the Unicode Character Database.
gucharmap Homepage - https://wiki.gnome.org/Gucharmap
gucharmap GitHub - https://github.com/GNOME/gucharmap
GNOME gucharmap (그놈 문자표)
시작하며
저는 한자(漢字/汉字)에 관심이 많은 개발자이며, 취미로 중국어(中國語,漢語,汉语, Chinese)와 일본어(日本語, Japanese)를 배우고 있습니다.
저는 어릴때 중국어에서 사용하는 한자(漢字·汉字,hànzì,ㄏㄢˋㄗˋ)와, 일본어에서 사용하는 한자(漢字・かんじ, kanji), 그리고 한국어에서 사용하는 한자(漢字, hanja)가 다르다는 것을 깨닫고, 어릴때부터 한자에 대하여 관심을 갖게 되었습니다.
어릴때 집에서 구독하는 조선일보 기사를 보면 나라 국(國)에 대한 한자를 国로 사용하고, 더불, 줄 여(與)에 대한 한자 与를 쓰는 경우를 보았습니다.
조선일보에서 한자를 표준에 안맞게 쓸까 궁금했습니다. 여기에 대하여 아버지에게 여쭤보면 "조선일보가 일본의 기계로 찍어내서 약자를 쓴다"라고 하시며 "한자 쓸때에는 약자를 쓰면 안된다"라면서 정자체[正字體,일본에서는 구자체(舊字體,旧字体),중국에서는 번자체(繁字體)로 부름]를 배워야 한다고 강조한 적이 있습니다.


위의 조선일보에서 여(與)를 "与"로 표기를 하였고, 동아일보에서 여(與)를 "與"를 표기하였습니다.
이후, 고등학교때에 제2외국어로 중국어를 배우고, 대학교때에도 중국어 수업을 들었습니다. 중국 대륙에는 한자를 간체자(簡體字,简体字)로 바꿔서 일상생활에 사용한다 것을 알게 되곤, 한자의 모양이 다양해지고 파편화되고 있구나를 깨달았습니다.
예를 들어 차례, 버금 차(次)에 대한 한자 표기는 각 나라마다 다릅니다.

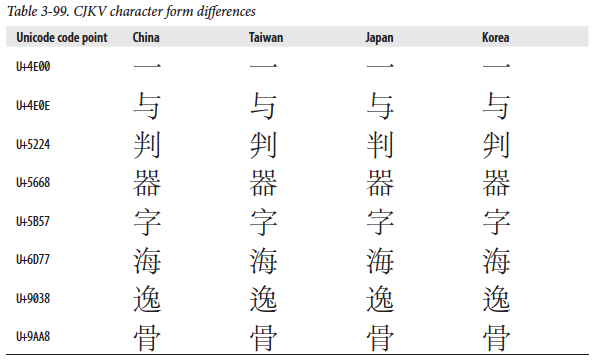
순서대로 일(一), 여(与,與), 판(判), 기(器), 자(字), 해(海), 일(逸), 골(骨)로 읽습니다.
(각 나라의 한자 모양을 보면, 현재의 Android OS탑재 단말기들이 제조사마다 다르게 구현되어 파편화 되고 있다는 것과 비슷한 느낌으로 받아들이면 될것 같습니다.)
그놈(GNOME)을 처음 접할때...
대학교 입학때, 리눅스 데스크탑을 접하게 되면서 문자표(GNOME gucharmap, KDE kcharselect)를 접하게 되었습니다.
위의 문자표에서 여러가지 한자가 나오면서, 한자에 대한 한국어 표기가 나옵니다만, 영어로 나와서 실망했고, 로마자표기법이 현재 대한민국에서 사용하고 있는 로마자 표기법이 아닌 것이 나와 당황한 기억이 납니다.
시간이 지나며, 중국어 수업을 들으며 간체(简体字)와 번체(繁体字)의 차이에 대하여 관심을 많이 가지게 되었지만, 컴퓨터로 어떻게 처리할지는 그 당시에 생각을 하지 않았습니다.
이후 대학원 다닐때, 저는 CJKV Information Processing이란 책을 알게 되었습니다.


저는 이 책을 쭉 훑어보다 머릿속에 충격을 받는 다는 표현이 어떤 것인지에 대하여 알게 되었습니다.
앞부분에는 동아시아 국가에서 사용하는 언어에 대한 인문환경, 표준에 대한 내용이기때문에 기본적인 한자, 중국어와 일본어를 알고 있어서 읽는 것에 그렇게 큰 어려움이 없었습니다.
컴퓨터로 일본어, 중국어, 한국어를 어떻게 처리할지에 대하여 정리한 책인데, 책의 저자가 미국인이라는 것에 놀라도, 한국에서 한국어로 이런 책이 나온 적이 없는데, 미국인이 작성했다는걸 보고 충격을 아주 쎄게 받았습니다.
이 책을 보면서, 미국인이 동아시아문자처리에 대한 정리를 너무 잘했다는 생각이 들면서, 한국어에 대한 처리에 대한 책을 쓰고 싶단 생각을 예전부터 하였습니다.
이후 2012년도 한국 펄 워크샵(Korea Perl Workshop)에서 운이 좋게 "동아시아 문자 처리"라는 주제로 발표를 하게 되었습니다.
(2012년도에는 얼떨결에 한국 펄 워크샵에서 발표를 하면서, 2012년 펄 크리스마스 달력에 글 "열네번째 날: 동아시아 언어의 로마자 변환에 도전해보자!"를 작성하게 되었습니다)
@studioego 혹시 펄 워크샾에서 발표라도 해주실 수 있으신지요?
— JEEN (@JEEN_LEE) 2012년 10월 8일
Perl워크샵에서 발표를 하게되면서 Unicode Consortium에서 정리한 한자에 대한 사전을 만들어 볼까하는 생각을 했습니다.
이후 시간이 지나, 대만(臺灣,Taiwan)의 해커집단G0V에서 나온 Moedict(萌典)을 보고는 충격을 많이 받았지요.
어튼, 서론(序論)이 길었습니다.
한자 관련 정보는 어디서?
저는 웹상에서 한자(漢字)에 대한 정보에 대한 웹사이트 만들어야겠다는 생각을 했습니다.
그런데 한자 정보에 대한 사이트를 어떻게 만들어야 할까? 이런 고민을 쭉 하게 되었지요.
유니코드 컨소시엄(Unicode Consortium)에서 공개한 유니한 데이터베이스(Unihan database, 한자정보가 정리된 데이터베이스) 정보를 조사해봤습니다.
The Unicode® Standard Version 9.0 – Core Specification http://www.unicode.org/versions/Unicode9.0.0/UnicodeStandard-9.0.pdf
The Unicode Standard, Version 9.0 - Code Charts - http://www.unicode.org/Public/UCD/latest/charts/CodeCharts.pdf
UAX #38: Unicode Han Database (Unihan) - http://unicode.org/reports/tr38/
UAX #44: Unicode Character Database - http://www.unicode.org/reports/tr44/
Unicode® Standard Annex #41 COMMON REFERENCES FOR UNICODE STANDARD ANNEXES - http://unicode.org/reports/tr41/tr41-19.html
CJK Unified Ideographs - http://www.unicode.org/charts/PDF/U4E00.pdf
Unicode 최신 정보 FTP - http://www.unicode.org/Public/UCD/latest/
[Wikipedia] CJK Unified Ideographs - https://en.wikipedia.org/wiki/CJK_Unified_Ideographs
Python의 유니코드(Unicode) 관련 자료도 참조하게 되었습니다.
http://farmdev.com/talks/unicode/
Pragmatic Unicode http://nedbatchelder.com/text/unipain.html
유니코드 컨소시엄에서 정의된 파일과 가이드를 봐도 어떻게 만들지 감이 잡히지 않았습니다.
일단, 자유 소프트웨어(Free Software)로 구현된 GNOME gucharmap, KDE kcharselect가 후보군으로 떠오르군요.
위의 구현물의 소스코드를 보고 어떻게 한자 정보에 대한 사이트를 만들어볼까 고민을 해보게 됩니다.
KDE 문자표 kCharSelect - a tool to select special characters from all installed fonts and copy them into the clipboard on KDE
https://utils.kde.org/projects/kcharselect/
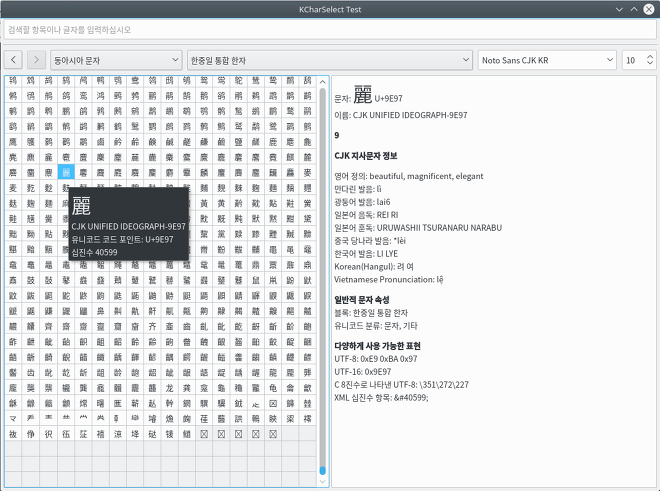
GNOME 문자표 gucharmap - the GNOME Character Map, based on the Unicode Character Database. https://wiki.gnome.org/action/show/Apps/Gucharmap
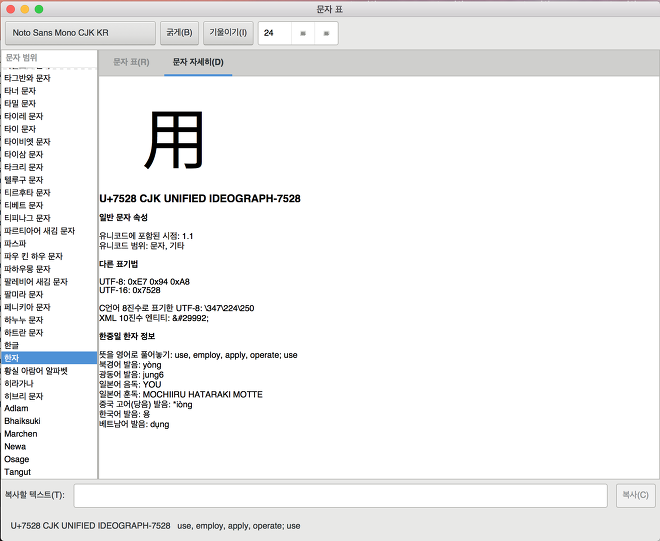
오픈소스 프로젝트에 소스코드 분석해볼까?
저는 자유 소프트웨어인 KDE kcharselect, GNOME gucharmap의 git mirror를 forked했습니다.
GNOME gucharmap git mirror - https://github.com/GNOME/gucharmap
KDE kcharselect git mirror - https://github.com/KDE/kcharselect
이후 KDE kcharselect의 소스코드와 GNOME gucharmap의 소스코드를 일단 확인했습니다.
KDE kcharselect의 소스코드는 C++(QT Library), Python 스크립트로 구성되어 있습니다.
Python 스크립트로 Unicode 관련 txt파일[UnicodeData.txt, NamesList.txt, Blocks.txt, Unihan_Readings.txt (you need to uncompress it from Unihan.zip)]을 읽고, 자체적으로 사용하는 구조체를 이용하여 데이터베이스 파일 생성하는걸 확인하였습니다.
GNOME gucharmap의 소스코드는 C(GTK+ Library), Perl 스크립트로 구성되어 있습니다.
gucharmap에서는 Unicode Consortium에서 정의한 파일 Blocks.txt, NamesList.txt, Scripts.txt, UnicodeData.txt, Unihan.zip 파일을 이용한다고 나와 있습니다.
Perl 스크립트로 Unicode 관련 txt파일을 읽어 들인후 여러 C언어 파일을 생성하는 것이 인상적이였습니다.
Unicode Consortium에서 제공하는 파일중 어떤 파일을 사용하는가? | |
GNOME gucharmap |
KDE kcharselect |
UnicodeData.txt NamesList.txt Blocks.txt Scripts.txt Unihan.zip |
UnicodeData.txt NamesList.txt Blocks.txt Unihan_Readings.txt |
GNOME gucharmap, KDE kcharselect에서는 한자(漢字/汉字, CJK Unified Ideographs)에 대한 내용은 Unihan.zip파일 내부의 Unihan_Readings.txt의 내용을 참조하는 것을 확인 하였습니다.
저는 유니코드 컨소시엄에서 정의한 Unihan.zip 내부의 한자를 읽는 방법을 정의한 Unihan_Readings.txt파일을 읽고, 내부구조를 확인해보았습니다.
내부 구조를 확인해보니 한자에 대하여 여러가지 읽는 방법에 대한 정의가 나와 있습니다.
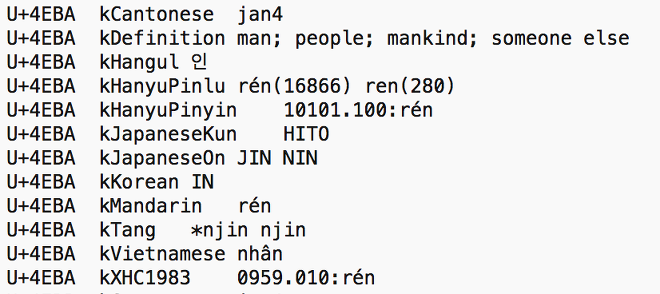
kCantonese, kDefinition, kHangul, kHanyuPinlu, kHanyuPinyin, kJapaneseKun, kJapaneseOn, kKorean, kMandarin, kTang, kVietnamese, kXHC1983
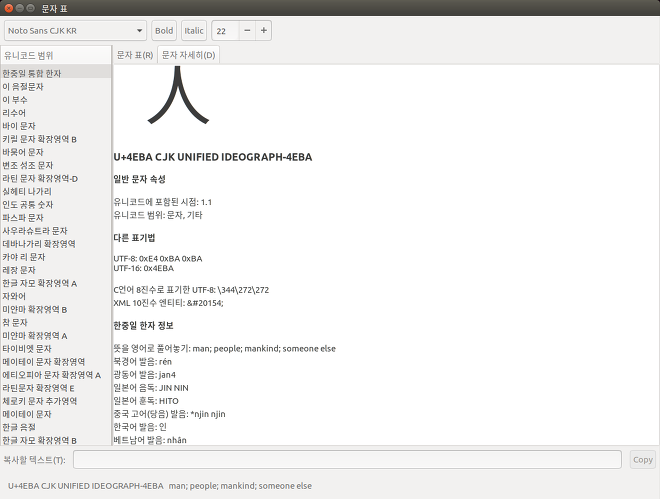
위의 정의 중에 한자에 대한 한글 표기(kHangul) 및 베트남어 발음표기(kVietnamese)가 존재함을 확인하였습니다.
예제) 사람 인(人)에 대한 유니코드 컨소시엄(Unicode Consortium)의 읽는 방법 정의
그런데 GNOME gucharmap, KDE kcharselect에서는 한국어의 로마자 표기가 지금은 주로 사용하지않은 방식인 예일대 표기법을 사용하고 있었으며, 베트남어의 발음표기가 추가 되지 않은 것을 확인하였습니다.
오픈소스 프로젝트에 소스코드 추가해보자!
저는 GNOME gucharmap, KDE kcharselect 2개의 프로젝트에서 Unihan_Readings.txt파일을 읽어들이는 소스코드를 분석후, 한글과 베트남어 발음 표기를 추가하게 되었습니다.
GNOME gucharmap에서는 Unihan_Readings.txt파일을 읽어들이는 C, Perl코드를 수정하였습니다.
버그질라 보고: https://bugzilla.gnome.org/show_bug.cgi?id=773380
추가한 소스코드: https://github.com/GNOME/gucharmap/commit/b3614d114bc2158f8e5c4b98797019f3a71d0ba7
KDE kcharselect에서는 Unihan_Readings.txt파일을 읽어들이는 python코드를 수정하였습니다
수정한 소스코드
1) kcharselect - https://github.com/studioego/kcharselect/commit/470b8ac5ad2bdf646a64abdfd4297ad2fd9148e0
2) kwidgetsaddon - https://github.com/studioego/kwidgetsaddons/commit/0ff990d063d8ba1f6d4a15c1144e0064fd844f9c
오픈소스 프로젝트에 소스코드 제출해보기
저는 KDE kcharselect, GNOME gucharmap 소스코드를 github에 커밋하였고, 이후 KDE 개발자와 GNOME 번역자(GNOME Korean Translator)에게 소스코드 커밋 요청을 했습니다.
Pull Request요청한 GNOME gucharmap github 소스코드 https://github.com/studioego/gucharmap
Pull Request요청한 KDE kcharselect github 소스코드 https://github.com/studioego/kcharselect
KDE쪽에서는 코드 충돌의 우려 및 기존 데이터파일의 배포 중단을 이유로 커밋이 거절되었습니다.
그러나 GNOME쪽에서는 GNOME Asia에서 활동하는 한국인 번역가 조성호(Seong-ho Cho)님의 도움으로 운이 좋게 커밋 성공하였습니다.
Reference: http://osdir.com/ml/commits.gnome/2016-11/msg01983.html
Subject: [gucharmap] Created tag 9.0.2
The unsigned tag '9.0.2' was created.
Tagger: Christian Persch <chpe@xxxxxxxxxxxxx>
Date: Mon Nov 7 19:20:01 2016 +0100
Version 9.0.2
Git-EVTag-v0-SHA512:
d889842de54cd9e5bbf253a098c13a7da91257c945b010b2d21d3f3607487d8ab47b4ba91548f9f65bf4cf70f14bece37e24907639428e6bba5b940acacfdc1e
Changes since the last tag '9.0.1':
Christian Persch (2):
Post release version bump
build: Pass --with-unicode-data down to distcheck configure
DaeHyun Sung (1):
charmap: Add korean hangul and vietnamese pronunciations
Marek Černocký (1):
Updated Czech translation
Piotr Drąg (1):
Update Polish translation
Sveinn í Felli (1):
Update Icelandic translation
_______________________________________________
commits-list mailing list (read only)
https://mail.gnome.org/mailman/listinfo/commits-list
드디어 저는 오픈소스 개발자가 되었으며 GNOME Contributor가 되었습니다.
원래는 웹상에서 한자에 대한 정보 보여주는 개발을 시작하려고 했고, 개발 시작전에 KDE kcharmap, GNOME gucharmap에 대한 소스 분석으로 하다보니, GNOME 개발에 기여를 하게 되었습니다. 운좋게 자유소프트웨어 개발자로 얻어걸린 격입니다.
GNOME 문자표(GNOME gucharmap)에 한자(漢字)의 한글 표기 및 베트남어 표기를 진행하다보니, 웹 상에서 한자 정보를 보여주는 서비스 구현에 대한 많은 성찰을 하게 되었습니다.
올해 안에 한자(漢字, Chinese Character)에 대한 정보 보여주는 서비스를 만든다고 도메인을 구입 및 배포하려던 계획들이 이번 GNOME gucharmap의 한글 및 베트남어 지원를 계기로, 내년에 한자 정보 서비스 사이트를 개발하기로 하였습니다.
계획은 미뤄졌지만, 리눅스 생태계의 자유 소프트웨어에 기여를 하였다는 것에 큰 의의를 둡니다.
이전에도 오픈소스(gwibber - https://code.launchpad.net/~sungdh86/gwibber/urlshorter-durl )에 기여를 한 적이 있었으나, 리눅스 배포판 설치할때마다 들어가는 문자표에 제 이름을 남기고 기여하기는 처음입니다.
아래는 GNOME gucharmap에 제가 작성한 소스가 포함된 부분에 대한 정보화면입니다.
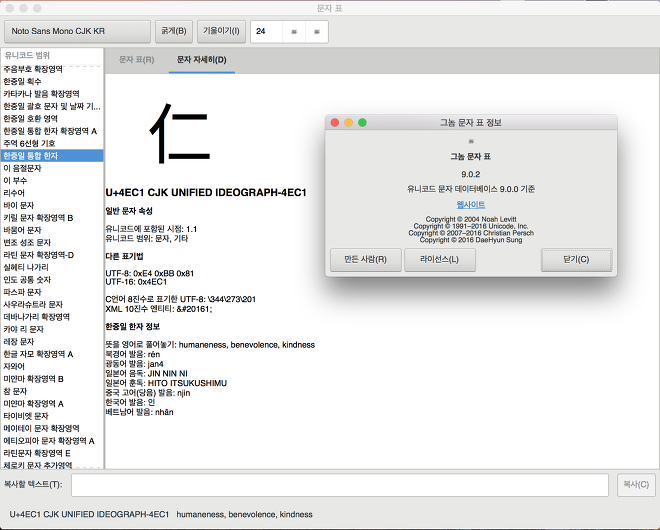
"Copyright ⓒ 2016 DaeHyun Sung"이 추가되니 정말 기쁩니다.
정리하며
"소 뒷걸음질 하다 쥐잡은 격"과 같이 우연히 C, C++, Perl, Python코드를 확인하다보니 오픈소스 프로젝트인 GNOME gucharmap에 한글 표기와 베트남어발음표기를 추가하게 되었습니다.
GNOME gucharmap, KDE kcharselect소스코드를 분석하다보니, 제가 원래 목표로 한 Python, Perl용 한중일월(中日韓越, Chinese-Japanese-Korean-Vietnamese) 라이브러리를 개발을 하는데 많은 도움이 되었습니다.
내년도에 더욱 더 성장을 하여 제가 목표로 하는 한자 정보 라이브러리(Python, Perl, Java, Ruby, etc) 개발 및 한자관련 홈페이지가 나올수 있도록 노력을 하겠습니다.
추가내용(2016.12.18)
GNOME한국(GNOME Korea)에서 번역가로 활동하시는 조성호(Seong-ho Cho) 한국 그놈 커뮤니티 블로그에 제가 GNOME gucharmap의 기능추가 (한글 및 베트남어 발음 지원)에 대한 내용(새로운 그놈 커미터 환영)을 작성하셨습니다.
앞으로 GNOME Korea의 발전에 많은 노력을 하겠습니다.
ps. 저에 많은 영향을 주신 한국 펄 커뮤니티(#perl-kr)에 감사함을 전합니다. 펄 커뮤니티 덕에 유니코드와 한자처리에 지속적인 관심을 가지게 되었습니다.
ps2. 2010년도쯤? 모 회사에서 CJKV Information Processing책을 보여주셨던 GNOME contributor 차영호(가나초코,ganachoco)님께 감사함을 전합니다.
ps3. CJKV Information Processing 책을 주신 @y0ngbin 님께도 감사함을 전합니다
ps4. 2013년도에 일찍 하늘나라로 간 Perl Contributor @am0c군께 부채의식을 항상 느끼고 있습니다. (Obituary of Perl release note 5.18.0-RC4)
@am0c군이 펄 크리스마스 달력 2012년 12월 14일자 에 "열네번째 날: 동아시아 언어의 로마자 변환에 도전해보자!"를 편집을 했었습니다.
이후 잠수를 타다 2016년 펄 크리스마스 달력에 2개의 글을 기고 했습니다.
올해 2016년 펄 크리스마스 달력
2016년 12월 7일자, "일곱째 날: Perl로 유니코드(Unicode) 코드 포인트(code point)에 해당하는 글자를 확인해보자."
2016년 12월 14일자, "열네번째 날: Perl로 한글의 모든 글자를 출력해보자"
ps5. 박현우 @lqez님께서 한국 파이썬 사용자 모임 2014년 12월 세미나에서 발표한 'Dive into OpenSource' 발표 슬라이드를 보면 정말 공감할 내용이 많이 있어요!
ps6. 오픈소스 프로젝트를 통해 어쩌면 더 나은 개발자가 되고, 더 많은 사람을 만나, 더 나은 인격체가 될지도 모른다고 하던데, 노력을 해야겠죠?
이희승(Trustin Lee, Author of Netty) - 새 오픈 소스 프로젝트 시작하기
----
English post.
I add GNOME gucharmap's new features.
1. add Korean Alphabet(Hangul, Hangeul, 한글)
2. add Vietnamese Pronunciation
gucharmap based on UNICODE Consortium's specification.
I read Unicode Consortium's Unihan Databases file. (Unihan_readings.txt)
Unihan_readings.txt file includes CJK Ideography's english meanings and pronunciations (such as Chinese, Japanese, Korean, Vietnamese, etc. East Asian cultural sphere's languages)
I found lack of Korean Hangul and Vietnamese pronunciation at GNOME gucharmap.
so, I add Korean Hangul, Vietnamese pronunciation in GNOME gucharmap.
It's amazing. I add my name "Copyright ⓒ 2016 DaeHyun Sung" in GNOME gucharmap.
I'm Open Source Developer and gucharmap contributor! Also GNOME Developer!
The following is My Gucharmap source code commit log.
Subject: [gucharmap] Created tag 9.0.2
http://osdir.com/ml/commits.gnome/2016-11/msg01983.html
ps1. Now, I summited KDE kCharSelect's new features. but rejected.
because, kCharselect Committer says "this will break distributions that update the data file separately from the library code."
Maybe KDE kCharSelect will change some features.
KDE Committer says "If you have additional ideas which other k* fields from Unihan.txt for CJK languages are useful to be included in KCharSelect, your input is welcome either on kde-utils-devel list, or on kde-frameworks list." to me.
If KDE kCharSelect's new version released, I'll share some East-Asian(CJKV) information processing for committers.
Unihan_Readings.txt included in Unihan.zip defines the notation and pronunciation of East Asian languages such as Chinese, Japanese, Korean, Vietnamese.
Unihan_Readings.txt’ has some properties.
Such as
kCantonese, kDefinition, kHangul, kHanyuPinlu, kHanyuPinyin, kJapaneseKun, kJapaneseOn, kKorean, kMandarin, kTang, kVietnamese, kXHC1983.
I add Unihan_Readings.txt defined kVietnamese property and kHangul property in this program.
Unihan_Readings.txt’s property kVietnamese describe Vietnamese character(Quốc ngữ) pronunciation. this property defined Unihan version 3.1.1. Now Unihan database version is 9.0.0.
Unihan_Readings.txt’s property kHangul describe Korean character(한글,Hangul) describe Korean pronunciation for this character in hangul.(Hangul is Korean Alphabet) this property defined Unihan version 5.0. Now Unihan database version is 9.0.0.
Because, Unicode Consortium presented kHangul property on Unihan version 5.
Unicode Unihan database document ( http://www.unicode.org/reports/tr38/ ) describe “kKorean” property.
“kKorean property’s description”
The Korean pronunciation(s) of this character, using the Yale romanization system. (See http://en.wikipedia.org/wiki/Korean_romanization for a discussion of the various Korean romanization systems.)
Use of the kKorean field is not recommended. The kHangul field, which is aligned to the KS X 1001 and KS X 1002 standards, is recommended to be used instead.
Now, Revised Romanization of Korean (RR, also called South Korean or Ministry of Culture (MC) 2000) is the most commonly used and widely accepted system of romanization for Korean instead of "Yale romanization system"[kKorean property] in Unihan database.
So, I add kHangul property and add “Korean Alphabet(Hangul)” notation.
“Unicode Consortium’s version9 guide chapter18. East Asia shows these paragraph.
In Vietnam, a set of native ideographs was created for Vietnamese based on the same principles used to create new ideographs for Chinese. These Vietnamese ideographs were used through the beginning of the 20th century and are occasionally used in more recent signage and other limited contexts.
Although the term “CJK”—Chinese, Japanese, and Korean—is used throughout this text to describe the languages that currently use Han ideographic characters, it should be noted that earlier Vietnamese writing systems were based on Han ideographs. Consequently, the term “CJKV” would be more accurate in a historical sense. Han ideographs are still used for historical, religious, and pedagogical purposes in Vietnam. “
So I read Unihan documentation specification, then support Vietnamese language.