이번에 컴퓨터공학과 3학년 2학기에 새로 생긴 전공과목인 네트워크 프로그래밍이란 과목을 수강하다가 Process를 이용한 웹서버 구현하는 과제를 하였습니다. 생각보단 어렵지는 안더군요. 예전에 Thread를 이용한 간단한 웹서버 구현한 것이있어서 Process로 바꾸는 데에는 금방 했습니다. (참고로
열혈강의 TCP/IP 소켓 프로그래밍이란 책을 참고했습니다.)
 열혈강의 TCP/IP 소켓 프로그래밍
열혈강의 TCP/IP 소켓 프로그래밍윤성우 지음 / 이한디지털리(프리렉)
나의 점수 : ★★★★★
처음 본 TCP/IP 소켓프로그래밍 책입니다.
소켓프로그래밍 공부하는데 서점에서 무슨 책으로 공부할지 고민을 하다가 이 책이 초보자들에게 괜찮은 듯하고 거기에 무료강의까지 제공해서 선택했습니다.
이 책을 쓰신 윤성우님은 열혈강의 C, 열혈강의 C++란 책으로 아주 유명하신 분이죠. (전 열혈강의 C, 열혈강의 C++를 보질 않았습니다. 그렇게 유명한 책이고 동기들이 다 본 책인데 ㅡㅡ;)
이 책은 다른 책보다 Windows와 Linux 두군데에서 어떻게 소켓프로그래밍 할지 설명이 잘 되어있습니다. 다른 책들을 보면 Linux에서만 돌아가거나 등등.
OS를 가리지 않고 C언어에서 소켓프로그래밍을 설명한 책이라서 학과 커리큘럼상에서 Linux밖에 배우지 않는 것을 커버하는 것이 좋다고 생각한다.
그러나 단점은 JAVA에서의 소켓프로그래밍은 알아서 공부해야겠죠?
이 책을 일주일만에 소스 다 치면서 400페이지 이상 읽었습니다. 정말 책이 술술 읽힌 것 같네요. 윤성우님의 명서라 할수 있습니다. 그러니까 열혈강의 C와 열혈강의 C++도 잘 쓰여졌을것이라 보네요.
그래서 과제를 하다가 World Wide Web을 오랬동안 쓴 저 조차도, HTTP Protocol에 대해선 전혀 모르고 써왔구나를 느꼈습니다.
(저는 하이텔부터 쓴 사람이라서^^, 국민학교 3학년때 아부지 회사였던 테헤란로 K**란 회사에 가서 인터넷이라는 것을 알게 되었다지요. 그때 인터넷 접속할때에는 DOS에서 win를 쳐서 Windows 3.1를 실행시키고, Winsock이란 프로그램을 띄우고 나서 전화선 모뎀으로 접속해야했던 과거 ^^ - 오덕의 기운이 초등학교때부터 시작 ㅡㅡ;)
현재 우리나라에서는 HTTP Protocol가 어떻게 정의되었는지에 대한 책들을 찾기 힘들더군요, 그래서 학교 도서관에서
HTTP The Definitive Guide란 책을 빌려서 보고 있습니다 :D
책 내용이 2002년 9월달에 나왔지만, 변하는 내용은 아니니까. 책을 보면서 당연하게 느낀 것들도 어떻게 정의되었는지를 알게 되었을때 재미가 있네요. 공부가 재미있다는 것이 이런건가? -_-;;
Process를 이용한 웹서버 과제를 하고 나서 HTTP를 사용해서 서버 정보를 가져와 파일로 저장하는 프로그램도 짜봤습니다만, 자주 쓰는 웹서비스도 이해를 안하고 썼다는 것에 충격.
1. HTTP Protocol이란?HTTP는 Hyper-Text Transfer Protocol의 약자로 WWW(World Wide Web)에서 사용되는 Protocol이다. HTTP/1.0은 RFC1945, HTTP/1.1은 RFC2068, RFC2616에 명시되어 있습니다.
일반적으로 포트번호는 80을 사용합니다.
실제로 쓰는 웹서버들은 포트번호를 명시해주어야 합니다. 예를 들어 네이버 주소는 원칙적으로 쓰면
http://www.naver.com:80/ 이렇게 포트번호 80를 명시해주면서 접속을 해야한다만
http://www.naver.com/ 이런식으로 표현하는 것도 포트번호가 80을 쓴다는 것을 암묵적으로 알기때문입니다.
자세한 내용은 RFC 문서를 읽으시는 것이 좋을 듯 합니다. 블로그에 포스팅하긴 엄청나게 방대한 양이라서요^^
HTTP/1.0 RFC1945 :
rfc1945.txt.pdfHTTP/1.1 RFC2068 :
rfc2068.txt.pdfHTTP/1.1 RFC2616 :
rfc2616.txt.pdf2. 웹서버를 이해하기웹서버란? HTTP Protocol을 기반으로 해서 웹 페이지가 들어있는 파일을 클라이언트에게 전송해주는 프로그램이라고 보면 됩니다.
지금, 이 글을 보는 여러분들은 인터넷 브라우저인 FireFox나 Internet Explorer를 사용하고 계실 것입니다. 이 인터넷 브라우저는 클라이언트 소켓프로그램에 해당됩니다. 임의의 사이트에 접속을 하려고 할때, 브라우저도 내부적으로 TCP/IP소켓을 생성하기 때문입니다. 다만 인터넷 브라우저가 지니는 특징은, 서버가 전송해주는 HTML문으로 이루어진 문서를 그대로 보여주지 않고 HTML문법에 맞게 변환해 준다는 것이죠.
3. 간단한 HTTP 실행과정HTTP는 클라이언트와 서버가 일정하고 예측 가능한 방식으로 정보를 교환하고 상호작용을 할수 있도록 허용하는 Method와 header의 집합을 정의하고 있습니다.
웹에서 볼수 있는 각 XHTML파일은 웹과 관련된 URL(Universal Resource Locator)을 가지고 있습니다. URL은 사용자가 접속하고자 하는 리소스(대부분 웹 페이지)에 브라이저가 접속할 수 있도록 하는 정보를 포함하고 있습니다.
예를 들면,
http://www.dal.kr/data/index.htmlhttp://는 웹 브라우저가 HTTP를 이용해 리소스를 요청해야한다는 것을 나타냅니다. 중간부분의 www.dal.kr은 서버 호스트 이름입니다. 호스트 이름은 리소스가 위치에 있는 컴퓨터의 이름인데, 이 컴퓨터가 보통 리소스를 간직하고 유지하기 때문에 호스트(Host)라고 합니다.
요청된 리소스 이름 /data/index.html (HTML문서)는 URL의 나머지 부분입니다. URL에서 이 부분은 리소스 이름(index.html)과 경로 (/data)를 확실해 구분해줍니다. 이 경로(path)는 웹 서버 파일 시스템에 있는 실제 Directory를 나타냅니다. 그렇지만 보안상의 이유로 경로는 대부분 가상 디렉토리(Virtual Directory)를 나타냅니다. 이 경우에, 서버는 해당 경로를 서버의 실제 위치로 해석하기 때문에 자원의 정확한 위치를 숨길수 있습니다. (Apache에서 VirtualHost인가 설정하면 해당 경로를 해석해서 표현합니다^^)
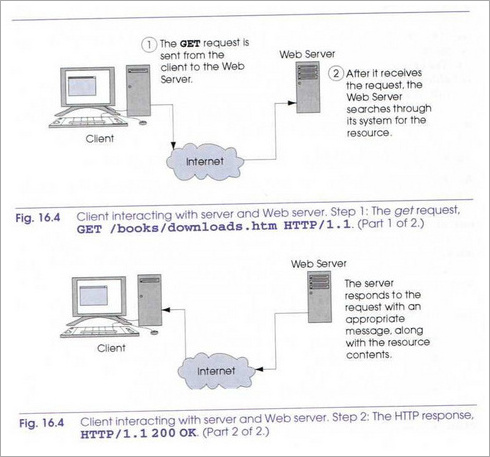
주어진 URL에 대해서 브라우저가 웹 페이지를 표현하기 위한 HTTP 트랜젝현을 어떻게 수행될까요?
아래 올려진 그림에서 잘 보여줍니다.
http://www.dal.kr/data/index.html를 접속한다고 생각합니다.
브라우저는 서버로 HTTP요청을 보냅니다. 그 요청은 이렇게 나타냅니다.
GET/data/index.html HTTP/1.1
host : www.dal.kr
GET이라는 단어는 리소스를 검색하고자 하는 클라이언트를 나타내는 HTTP Method입니다. 나머지 요청에서는 리소스의 이름 및 경로 그리고 프로토콜 이름과 버전 번호(HTTP/1.1)를 제공합니다.
(실험한 사이트들이 HTTP/1.0 을 써서 난감 ㅡㅡ;)
클라이언트가 서버에게 메시지를 주면 서버는 클라이언트에 요청 결과를 보내줍니다.
서버는 우선 한 줄로된 HTTP 버전과 그 뒤에 트랜잭션의 상태를 나타내는 숫자 코드와 구(phase)로 응답합니다.
HTTP/1.1 200 OK는 성공,
HTTP/1.1 501 Method Not Implemented 는 요청을 처리하는데 필요한 기능이 구현되지 않았음,
HTTP/1.1 404 Not found 는 특정한 위치에서 서버 자원을 찾을 수 없다는 응답을 알려줍니다.
아래는 제가 HTTP정보를 얻는 프로그램을 작성해서 돌려본 결과입니다. 제가 가는 사이트 마다 HTTP/1.1 지원하는 사이트가 없군요 ㅡㅡ; 다만 제가 일하고 싶은 오픈마루스튜디오는 HTTP/1.1를 지원하고 있었습니다 ㅠㅠ
host : www.dal.kr, path : /data/index.html
Get /data/index.html HTTP/1.0
HTTP/1.1 501 Method Not Implemented
Date: Sun, 23 Sep 2007 15:01:44 GMT
Server: Apache
Allow: GET, HEAD, OPTIONS, TRACE
Connection: close
Content-Type: text/html; charset=iso-8859-1
host : www.http-guide.com, path : /index.html
Get /index.html HTTP/1.0
HTTP/1.1 501 Method Not Implemented
Date: Sun, 23 Sep 2007 15:10:04 GMT
Server: Apache/1.3.37 Ben-SSL/1.57 (Unix) PHP/4.4.2 FrontPage/5.0.2.2624 DAV/1.0.3
Allow: GET, HEAD, POST, PUT, DELETE, CONNECT, OPTIONS, PATCH, PROPFIND, PROPPATCH, MKCOL, COPY, MOVE, LOCK, UNLOCK, TRACE
Connection: close
Content-Type: text/html; charset=iso-8859-1
host : www.openmaru.com, path : /index.php
Get /index.php HTTP/1.0
HTTP/1.1 200 OK
Date: Sun, 23 Sep 2007 15:24:31 GMT
Server: Apache/2.2.3 (Unix) PHP/5.1.6 mod_python/3.2.10 Python/2.4.3 DAV/2
X-Powered-By: PHP/5.1.6
Set-Cookie: TSSESSION=2039b9c23de52f6d7b8713126cf3b9b4; path=/; domain=openid.or.kr
Expires: Thu, 19 Nov 1981 08:52:00 GMT
Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0
Pragma: no-cache
Vary: Accept-Encoding
Connection: close
Content-Type: text/html; charset=utf-8
서버는 클라이언트에게 보내는 데이터에 관한 정보를 제공하는 하나 또는 그 이상의 HTTP헤더를 보냅니다. 위에 제가 HTTP정보를 얻는 프로그램을 작성해서 돌려본 결과를 보면 그 예를 볼수 있습니다.
Content-Type: text/html; charset=iso-8859-1
Content-Type: text/html; charset=utf-8 Content-Type헤더의 정보는 MIME(Multipurpose Internet Mail Extension) 타입의 컨텐츠를 확인합니다. 서버에서 보내진 각 데이터 타입은 MIME타입을 가지며 이 MINE타입을 통해 브라우저는 받은 데이터를 어떻게 처리할 것인지를 결정합니다.
헤더 다음의 빈줄은 서버가 HTTP 헤더 전공을 끝냈다는 것을 클라이언트에게 알려주는 것입니다. 그리고 나서 서버는 요청된 리소스의 내용들을 보냅니다. 리소스 전송이 완료되면 연결이 종료됩니다. 클라이언트 측 브라우저는 받은 문서를 해석하고 결과를 화면에 출력또는 전달해줍니다.
아래 그림은 웹 서버랑 브라우저랑 어떻게 연결하는지 보여주는 그림입니다 :D
책내용은 HOW TO C++ PROGRAMMING Forth Edition - Deitel 형제가 쓴 책 내용의 일부분 참조했습니다.
아 생각보다 방대한 양들이군요. HTTP/1.1로 구현한 웹서버는 기능을 많이 뺀 것이라 간단하게 프로그래밍 했다만, 제대로 구현하려면 몇줄을 작성해야할까 걱정이 되군요 ㅡㅡㅋ
이왕에 MFC로 윈도우즈에도 써볼까? -_-;;(그러다 밤샐래!)
자세한 내용은 위에 있는 RFC문서를 참조하시기 바랍니다. 영어 해석이 어렵다면 네이버 지식즐을 참조하시길 :D
열혈강의TCPIP소켓프로그래밍,
웹서버,
소켓,
클라이언트,
서버,
protocol,
socket,
server,
client,
HTTP,
HTTP1.1,
소켓프로그래밍,
WWW,
인터넷,
웹