이 글은 제 9회 삼성 소프트웨어 멤버십 공개 세미나에서 보았던 것에서 떠올린 생각들을 끄적 거렸습니다.

홍익대학교에서 설명회를 하였던 11월 25일 화요일 제 9회 삼성 소프트웨어 멤버십 공개 세미나
여기서 멀티미디어 정보검색기술에 대한 세미나를 듣게 되었습니다. 도대체 어떤 내용인지를 알고 싶어서 들어보았는데, 저에게 충격을 준 동영상을 틀어주더군요.
위의 동영상은 midomi에서 아이폰에서 음악 검색을 정확하게 해주는 것을 홍보하는 동영상인데 멀티미디어 정보검색기술을 설명하기 위해서 이 동영상을 세미나 도중에 틀어주게 되었습니다.
음성인식기술이 이렇게 발전했다는 것이 대단하게 느껴졌습니다. 흥얼흥얼 거리는 노래가 내가 모른다면 아이폰으로 검색하면 다 나오는 시대가 되었다는 것입니다.
Midomi.com 에 보시면 자세한 내용을 보실 수 있답니다.
Midomi mobile : the ultimate music search and discovery
With midomi, you can search for music in FOUR different ways.
- SING: just sing or hum a few seconds of a song, and midomi will find it!
- GRAB: hold your phone to a speaker playing original music for a few seconds, and midomi will identify what's playing!
- SAY: it's easier than typing. Just say the song or artist name you're looking for, and midomi will find it!
- TYPE: The old fashioned way to search, but no need to spell it right. Just type a song or artist name the way it sounds, and midomi will find it!
Once you find a song, see the YouTube video, or buy it from iTunes. You can also see artist photos, albums, and biographies, even browse midomi.com user profiles, see their pictures, listen to their recordings, and lots of other cool things.

Chapter 27: Information Retrieval and XML Data Management. Slides come in five parts:
위의 Slide나 책을 보면 DBMS와 Information Retrieval의 비교가 나온다.
IR(Information Retrieval) |
DBMS |
| 주관적인 의미검색 (Imprecise Semantics) | 정확한 의미검색 (Precise Semantics) |
| 단어 검색 (Keyword Search) | SQL Query문에 의한 검색 |
| 비구조화 데이터 포맷으로 구성됨 (Unstructured Data Format) | 구조화된 데이터 (Structured Data) |
| 대개 읽기를 함. 때때로 문서들을 추가함.(Read-Mostly. Add docs occasionally) | 많은 수의 문서들이 수정,삭제, 추가등의 작업을 함. (Expect reasonable number of updates) |
| 결과중 최고 몇개만을 보여줌. (Page through top k results) | SQL Query문의 결과를 모두 보여줌 (Generate full answer) |
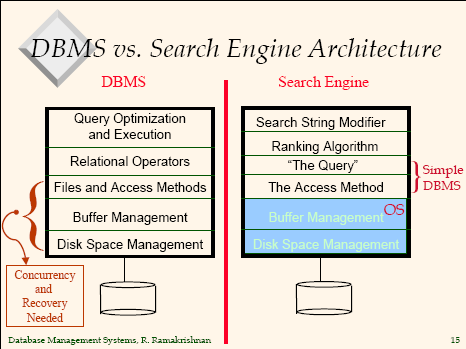
DBMS가 단순히 정보를 저장하고 쿼리(Query)문을 주면 쿼리문에 만족하는 정보를 모두 알려주지만, IR은 keyword를 주면 그 keyword들이 어디있는지를 저장한 Inverted File(역파일)에 있는 내용을 찾아내어 어디 있는지를 저장한 곳을 알려주는 차이점이 있습니다. IR는 참고로 정보를 추출하는데에 주관적으로 검색하기 때문에 정확한 검색이라는 것을 하긴 어렵습니다.
문서를 검색하는데에 Inverted File을 만들어서 관리하는 IR의 개념만 알고 있던 저에게 삼성소프트웨어멤버십 공개세미나에서 보여준 멀티미디어 정보검색은 저에게 충격자체였습니다.
멀티미디어인 소리, 사진을 검색하는 것을 웹문서에 그림과 같이 붙어있는 글자로 검색하여 찾는 것만 아니라 실제로 소리, 사진을 비교하여 검색 결과를 보여주는 것을 눈으로 보여줬기 때문입니다.
소리를 들려주고 검색하여 음악의 정보를 알려주는 midomi의 검색이나 삼성소프트웨어멤버십분이 보여준 음악검색을 보니 정말 신기하기 그지 없습니다.
멀티미디어 정보를 검색하려면 그 멀티미디어 파일을 알고 파일 접근하여 파일안의 내용을 인식하는 기술이 필요하지요. 그런데 멀티미디어 정보를 검색하는 것은 단순히 문자를 검색하는 것과 달라서 이런 위의 컴퓨터공학에서 처리하는 단어처리, 문서처리, DBMS, IR(Information Retrieval)내용뿐만 아니라 전자공학에서 배우는 신호처리, 이미지처리등을 알아야 검색을 할수 있더군요.
현재에도 웹의 발전으로 인하여 멀티미디어 정보들이 쏟아지는데, 미래에는 멀티미디어 정보검색이 필요할 것으로 예상됩니다. 현재의 정보검색이 Text기반으로 하여 이미지, 음악, 동영상 검색도 Text기반이라 Text에 달려 있는 것만 검색되어 검색 품질이 생각보다 낮습니다. 이런 Text기반의 검색은 원하는 결과를 찾기는 힘들 수 있습니다. 미래에는 멀티미디어파일을 직접 찾아서 검색하여 원하는 결과를 보여주는 검색엔진이 나올까 이런 생각도 해봅니다.
Text 문서를 찾는 정보검색은 이미 Google의 Page Rank 알고리즘으로 대개 원하는 검색 품질을 얻게 되었지만, 지금까지는 멀티미디어 정보검색은 완성단계에 오진 않았습니다. 그렇다만 미래에는 멀티미디어 정보검색을 하면 어떤 알고리즘, 어떤 신호처리, 이미지처리프로세스를 거쳐서 원하는 검색품질이 나오게 될 것 같은 생각을 해봅니다.
현재, Google의 Google Audio Indexing (GAudi)에서는 동영상에서 말하는 단어를 찾는 검색을 보여주고, 네이버의 얼굴사진검색, Midomi에서 보여주는 흥얼거리면 음악검색을 해주는 것에서 멀티미디어 정보검색을 시도하려는 노력을 하고 있습니다. 미래에는 나열한 것보다 훨씬 진일보적인 멀티미디어검색들이 많이 나오겠죠?
멀티미디어 정보검색에 대해 많은 생각을 해보게 되었습니다. 단순히 컴퓨터공학만 아니라 전자공학의 내용도 알아야 접근할 수 있는 내용들이 너무너무나 많더군요.
임베디드, 모바일쪽만 아니라 인터넷에서 컴퓨터공학과 전자공학이 이렇게 만날수 있다는 것을 알게 되었습니다.
대학 4년동안 컴퓨터공학을 전공하였어도 컴퓨터공학 내용을 전부 이해하지도 못하고 졸업하는 사람에게 전자공학적인 내용까지 알려준 멀티미디어 정보검색 세미나를 들으면서 아직도 공부할 것이 많다는 것을 느끼게 하였습니다.
'컴퓨터 > Web' 카테고리의 다른 글
| 네이버에서 pe.kr 도메인을 무료로 준다군요. (8) | 2008.12.11 |
|---|---|
| 추억속으로 사라지는 엠파스 (4) | 2008.12.10 |
| OpenID로 로그인 하는데 어떤 문제일까? (0) | 2008.11.13 |
| 케빈 베이컨의 6 단계 게임와 SNS (0) | 2008.07.09 |
| 레몬펜의 유령 드디어 Firefox 3지원~ (0) | 2008.06.22 |