관련 포스트
홍민희님 - Unicode 이해의 다양한 단계들
Unicode(유니코드)에 대해서 얼마나 아신가요?
홍민희님께서 작성한 Unicode 이해의 다양한 단계들 이란 글에서 심심풀이로 테스트를 하였습니다.
7단계중에서 저는 1~5단계까진 모두 경험해보고 해당되겠다는것을 알겠는데, 6~7단계는 잘 모르겠더군요.
5단계.
특정 문자셋을 사용하는 문자(열)을 바이트열로 인코딩하는 방식이 인코딩이며, UTF-8이 곧 Unicode가 아니라는 것을 아는 사람. Python에서unicode타입과str타입이 왜 함께 있는지 이해하며 잘 사용한다. 혹은 C/C++에서wchar_t[]/std::wstring으로 Unicode 문자열을 담아 사용하고 입출력 시에 그것을 인코드해서char[]/std::string으로 변환해서 쓸 줄 안다. (또한wchar_t가 곧 Unicode 문자를 뜻하는 것은 아니라는 것도 이해하고 있다.)
어릴때부터 컴퓨터를 사용해서 완성형과 조합형은 알았지만, 완성형은 DOS, 조합형은 한글과 컴퓨터사의 아래아한글에서 쓴다는것만 알았습니다.
그러다 MS사의 Windows95에서 한글 코드를 MS사에 맞는 문자코드(CP949, UHC)로 나온다고 해서 난리났던 잡지 기억도 나군요^^
문자 코드에 대해서 직접 접하게 된건 리눅스를 처음 설치하게 되었던 2004년 말 고3때였습니다.
2004년말 2005년초 정도부터 Linux에서 Unicode를 쓰는 것이 대세가 되어, 기본 서버에서 한글 설정이 UTF-8로 됨에 따라, 리눅스를 데탑으로 쓰는데 깨나 고생했던 기억이 나군요. (Windows와 Linux를 동시에 쓰는데 한글이 당연히 깨지는것이 부지기수)
(제가 처음 접한 Mandrake Linux에선 커널 2.4에서 2.6으로 올라가고 유니코드로 변경되는 등의 격변기를 겪던 시절)
그래서 UTF-8을 쓰면 Unicode를 완비할수 있겠다는 생각을 하였죠. (그러나 정태영님의 글 "컴퓨터 속의 한글"을 보는 순간 역시 나는 꼬꼬마였구나를 알게 되었죠@.@)
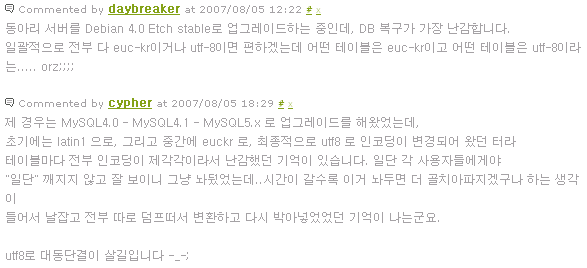
그러다 모 학회 서버를 관리하게 되었습니다. 하드디스크 문제가 생겨서 리눅스 설치후에 복구를 하니 이런 썅이라는 소리가 나오면서 인코딩 문제때문에 정말 애 먹었지요.
그당시 리눅스의 기본 설치는 UTF-8인데, 기존 자료들은 EUC-KR이니 당연히 안깨질리는 없구요.
iconv로 삽질 하고, MySQL덤프 뜬거 억지로 UTF-8에서 끼워 넣는 식으로 겨우 돌렸던 기억이 납니다.
그러다 2008년 Ruby, 2010년 Python를 공부하다 보니 인코딩이 특정 문자셋을 사용하여 문자열을 바이트열로 인코딩 하는 방식이 인코딩(Encoding)이라는 걸 그냥 알게 되더군요.
문자열과 문자셋, 유니코드 같은 건 많이 경험해보고, 삽질을 해보고, 직접 프로그래밍을 많이 해봐야, 이해를 쉽게 하게 되더군요.
말로만 들으면 왜 저렇게 해야하는지 이해를 못했다, 직접 부딫쳐봐야 Unicode, 문자셋, 인코딩의 개념를 제대로 알게 되더군요.
대학 1~3학년때 워낙에 문자 인코딩때문에 억수로 삽질을 한 덕택에 5단계까지 온듯 합니다.
6단계 Unicode에 여러 평면(plane)이나 카테고리(category), 스크립트(script) 등의 분류가 존재한다는 것을 알고 있다. UCD의 존재를 알고 있다.
와 7단계 Unicode전문가는 저도 잘 모르는 거라... (먼산)
아래는 블로그에서 썼던 문자 인코딩때문에 겪었던 삽질기록들 (대학 입학전에도 UTF-8의 존재는 알았고, 대학 2학년때 wchar_t로 사용했던 과거도 있는데 많이 쓴 기록은 없고, 있다는건 알았다 정도?)
2005/02/08 - [분류 전체보기] - [TIP]Gmail 사용시 한글이 깨질 때
2007/08/04 - [컴퓨터/DB] - MySQLdump할때 한글 깨짐 방지
2007/08/05 - [컴퓨터/DB] - 꼬인 DB를 복구 완료 및 셋팅중.
2007/08/06 - [컴퓨터/DB] - DB 문자셋을 통일 시켜버릴까?
'컴퓨터 > 프로그래밍' 카테고리의 다른 글
| MFC에서 웹캠으로 영상처리 작업하다 에러 생길경우. (1) | 2010.10.25 |
|---|---|
| Visual C++ 6.0에서 작성된 MFC를 VS2008,2010에서 컴파일오류시 (0) | 2010.10.18 |
| Inside the C compiler (0) | 2010.05.30 |
| C Programming의 내부를 파헤쳐보기 - Inside the C Programming (0) | 2010.05.30 |
| suvbersion 설치 및 사용법 링크 (1) | 2010.03.31 |