Homepage: http://dbeaver.jkiss.org/
DBeaver - 개발자와 DBA를 위한 무료 오픈소스(GPL) 데이터베이스 툴
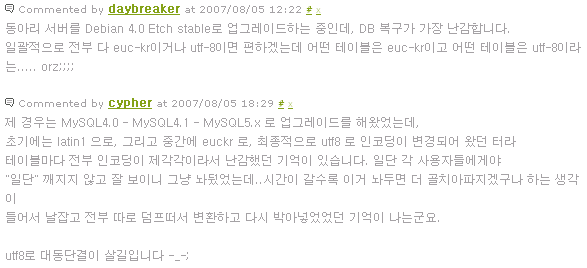
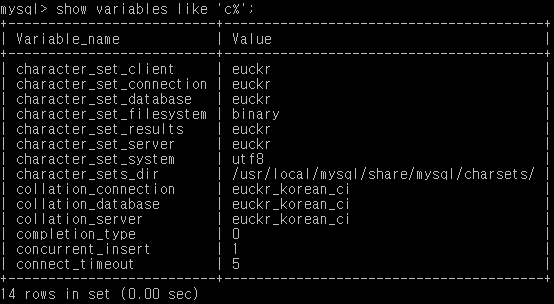
저는 Eclipse 플러그인으로 된 DBeaver를 사용하고 있음. Oracle, Mysql, PostgreSQL, SQLite, H2, Java DB등 여러종류의 DBMS를 지원하고 OS도 Windows, Linux, Mac OS 모두 지원합니다.
무료 GUI DB툴 치고는 ERD 보여주는 기능 및 BLOB 보여주는 기능등등 여러가지 기능이 좋아서 소개합니다.
아래는 DBeaver 홈페이지에 있는 소개
Overview
DBeaver is free and open source (GPL) universal database tool for developers and database administrators.
- Usability is the main goal of this project, program UI is carefully designed and implemented.
- It is freeware.
- It is multiplatform.
- It is based on opensource framework and allows writing of various extensions (plugins).
- It supports any database having a JDBC driver.
- It may handle any external datasource which may or may not have a JDBC driver.
- There is a set of plugins for certain databases (MySQL and Oracle in version 1.x) and different database management utilities (e.g. ERD).
Supported (tested) databases:
- MySQL
- Oracle
- PostgreSQL
- IBM DB2
- Microsoft SQL Server
- Sybase
- ODBC
- Java DB (Derby)
- Firebird (Interbase)
- HSQLDB
- SQLite
- Mimer
- H2
- IBM Informix
- SAP MAX DB
- Cache
- Ingres
- Linter
- Teradata
- Vertica
- Any JDBC compliant data source
Supported OSes:
- Windows (2000/XP/2003/Vista/7)
- Linux
- Mac OS
- Solaris
- AIX
- HPUX
General features:
- Database metadata browse
- Metadata editor (tables, columns, keys, indexes)
- SQL statements/scripts execution
- SQL highlighting (specific for each database engine)
- Autocompletion and metadata hyperlinks in SQL editor
- Result set/table edit
- BLOB/CLOB support (view and edit modes)
- Scrollable resultsets
- Data (tables, query results) export
- Transactions management
- Database objects (tables, columns, constraints, procedures) search
- ER diagrams
- Database object bookmarks
- SQL scripts management
- Projects (connections, SQL scripts and bookmarks)
MySQL plugin features:
- Enum/Set datatypes
- Procedures/triggers view
- Metadata DDL view
- Session management
- Users management
- Catalogs management
- Advanced metadata editor
Oracle plugin features:
- XML, Cursor datatypes support
- Packages, procedures, triggers, indexes, tablespaces and other metadata objects browse/edit
- Metadata DDL view
- Session management
- Users management
- Advanced metadata editor
Other Benefits:
- DBeaver consumes much less memory than other popular similar software (SQuirreL, DBVisualizer)
- Database metadata is loaded on demand and there is no long-running “metadata caching” procedure at connect time
- ResultSet viewer (grid) is very fast and consumes very little ammount of memory
- All remote database operations work in non-blocking mode so DBeaver does not hang if the database server does not respond or if there is a related network issue
License
DBeaver is free software; you can redistribute it and/or modify it under the terms of the GNU Lesser General Public License as published by the Free Software Foundation; either version 2.1 of the License, or (at your option) any later version.
DBeaver is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
'컴퓨터 > Open source' 카테고리의 다른 글
| 미국 정부, Cloud Platform 구축 (0) | 2015.10.12 |
|---|---|
| 그놈 3.18 소개(Introducing GNOME 3.18) 동영상 (0) | 2015.10.04 |
| 소프트웨어 저작권과 오픈소스 라이선스에 대한 정리가 잘된 슬라이드 (0) | 2014.08.19 |
| [후기] 오픈소스 개발이라, 저도 한번 참여해봤는데요. (0) | 2014.01.05 |
| 존 카멕(John Carmack) - Doom 3 게임 엔진 오픈소스 공개 준비 완료. (1) | 2011.11.02 |




 My SQL 5.0 레퍼런스 메뉴얼
My SQL 5.0 레퍼런스 메뉴얼