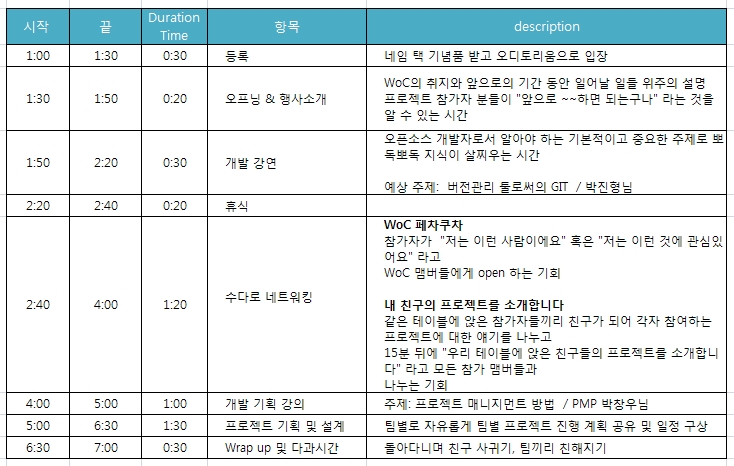
행사명 : TatterCamp(태터캠프)
주최 : 태터네트워크재단(TNF)
후원 : 다음 DNA lab, 구글 코리아 및 다음 티스토리팀
일시 : 12월 6일 토요일 13:40~18:10
장소 : Daum 홍대 UCC오피스 (홍익대학교 홍문관 14층)
이번 제 6회 태터캠프에 늦게나마 참석을 하게 되었습니다.
이로서 4,5,6회 태터캠프에 참가 도장을 찍게 되었더군요.
이번에 태터캠프가 홍문관 14층에서 열린다고 해서 너무나 좋아라 했습니다.
예전 5회 태터캠프 끝나고 나서 gofeel님께서 홍대에서 할 예정이라는 소리를 하여서 설마 했다가 결국은 홍익대학교에서 개최를 하게 되었다는 소리에 만세를 외쳤습니다.
그러나 날짜가 에러. 제가 다니는 홍익대학교라는 장소에서 행사를 해서 너무 좋아라 했다만 12월 6일은 교양 시험이 있었다는 엄청난 사실에 OTL
싸이버강좌 기말 고사 강의실 공지
| 기말 |
12월 6일 (토) |
12월 7일 (일) |
| 9:00~10:00 |
영화학개론 |
동양문화사 |
| 11:00~12:00 |
인간관계론 |
패션과 개성연출 |
| 13:00~14:00 |
생물학 |
심리학의 이해 |
| 15:00~16:00 |
조직과 리더쉽 |
협상론의 이해 |
| 16:30~17:30 |
인터넷커뮤니케이션의 이해 |
생명공학의 이해 |
| 18:00~19:00 |
컴퓨터입문 및 실습 |
고전음악의 이해 |
| 19:30~20:30 |
언어의 이해 |
Fashion Art |

꿈도 희망도 없어. 태터캠프 갈수 있을까?
결국은 가긴 했습니다만, 너무 늦게 가서 죄송할 따름이었습니다.
가는날 도 장날이라서 원래는 학교에 2시 도착을 하려고 했다만, 지하철 사고로 인해여 예정시간보다 1시간 늦게 도착하는 일도 발생하였습니다.
학교에 4시 도착하여 30분동안 강의실에서 시험공부하다가 35분에 시험시작. 시험을 15분만에보고 10분기다리다 바로 나갔습니다.
시험 끝나고 나선 태터캠프가 열리는 홍문관 14층으로 바로 달려갔지요.
홍문관 14층에 도착하니 이미 거의 다 끝나가는 분위기에 반갑게 맞이하는 Tistory 관계자 분들을 문앞에서 뵙고, 날뷁님도 만났습니다. 예전에 만난 사람들은 다 만난 것 같은 느낌?
CK님의 발표도중에 들어왔기 때문에 앞에 무슨 이야기를 했는지 연결이 안되었다만 열심히 들으려고 했습니다.
CK님의 발표
"이번에 오픈 웹아시아 행사를 해보면서 한국의 SNS를 소개해 달라는 말을 해서 Cyworld라는 말을 할수 없었습니다. 국내의 제대로 된 SNS를 보지 못하였습니다. 제가 모르는 것도 있으니 양해 바랍니다." 이런 말씀을 하셨지요.
관심사 기반의 소셜 네트워크에 대해서 말씀하면서 기존의 서비스와 연동 이런 이야기를 하였습니다.
마지막에는 韓·中·日기반으 소셜네트워크를 생각한다는 이야기도 하였습니다.
CK님의 발표가 끝나자 마자 겐도님의 발표가 있었습니다.
Google Textcube.com Labs
Google Textcube.com에서의 실험적으로 준비하는 내용에 대해서 설명을 하였습니다.
목차
- Project Garnet - Textcube.com
- skin
- Data Portability
- Service Integration
1. Textcube.com 2.0 Garnet
Skin format & Engine을 T2Skin이라는 것으로 변경
Data format : TTML/Garnet
플러그인 컨셉변경 : Gadget + alpha
블로그 서비스
- Social features
- Intelligent Statistics
- Additional Editor features
※ 예전 Tatter tools, Tistory, TextCube와 다르게 스킨포맷을 변경하였고, 데이터 포맷도 변경, 플러그인 컨셉도 위젯형태로 바꾸고, 통계추가, 에디터에 추가적인 특징을 하였다고 설명하시더군요.
sidebar에서 자기가 설정한 내용을 날라가지 않도록 하기 위하여 Data Schema를 변경시켰다고 하고, 로그인 할때 Session System을 사용 (HTTPS Protocol사용)등등 새로운 특징들을 활발하게 진행한다고 말씀하셨습니다.
Skin
TC - 기능 구현의 제한
서비스 - 서비스 스킨과의 호환성, 서비스 독자 기능의 제한
디자이너 - 시스템 별로 스킨 제작
사용자 - 실수 = 사용불능
※ 예전 Tatter tool나 Textcube에서 스킨을 제작하려면 기능의 제한이 있고 스킨도 시스템 별로 제작하는 불편한도 있고, 스킨을 제작하다가 실수를 하면 사용을 못하게 되는 위험한 점이 있다고 발표를 하셨습니다. 그래서 나온 것이 TTSkin 2.0 이라고 하더군요.
TTSkin 2.0
- Strict HTML + custom CSS
- 제약된 내용편집
- 강제된 DOM Structure
- CSS 위주의 디자인
그러나 비공개, TTSkin v1기반과 호환성 전혀 없음
실험중심으로 TTSkin 2.0을 만들고 있음
- 서비스 시스템의 특성 분석
- 사용자의 편의성 실험
- 디자이너 대상 실험
결과로 TTSkin v2은 어떻게 될련지는 모르겠다고 하셨습니다.
여기서 Daybreaker님과 이야기가 나오면서 회사 댕기는 공돌이 vs 학생인 공돌이 와의 디자인에 대한 논쟁(?) 도 있었답니다.
데이터를 쉽게 옮길 수 있도록 해야하는데 Textcube 2.0 Garnet에서는 데이터 이동, 구조에 대해서 어떤 활동을 펼쳤는지를 설명하셨습니다.
Data Portability
4GB보다 큰 데이터들 처리를 못함
Server timeout connection or reset
서비스 간 차이
TTXML자체 버그
Export/Import버그가 있음
이런 내용을 왜 생각을 하였나?
시스템 간 데이터 교환을 하기 위해서
me2day↔TatterTools
데이터 이전이 아닌 Push & Pop
- Micromedia site : Wing
분산과 집중
- 나의 글을 여러 곳으로
- 각각에서 일어나는 활동을 한 곳으로
TTXML/Garnet
다른 서비스간 데이터 이동성 실혐
- 서비스의 데이터 포맷 확장
대용량 Blog Data에 대한 고민
데이터 안정성
BlogAPI → getPost
- Textcube와의 Mash up
Integrate with Google products
- 구글의 서비스과 통합에 대해서 간략하게 말함
제가 들었던 강의 내용이였고, 제대로 들은 강의는 겐도님의 강의밖에 없었더군요.
그리고 나서 기념사진을 찍었고, 기념 사진 찍고 나서는 바로 학교로 달려가서 기말고사 공부를 하였습니다 ㅠㅠ
끝나고 난 후에 기념품을 받았습니다^^

기념품은 구글 코리아 볼펜, 구글 담요, 구글 핸드폰 클리너, 구글 노트입니다.
다음사옥에서 구글 상품을 받은 흔치 않는 경험을 해보았습니다.
오늘 테터리안, 블로고스피어분들, 텍스트큐브, 니들웍스, 구글, 다음 티스토리 관계자분들 수고많으셨습니다.
늦게 참석을 해서 제대로 듣지는 않았지만, 예전에 뵈었던 분들을 뵈어서 반가웠습니다.